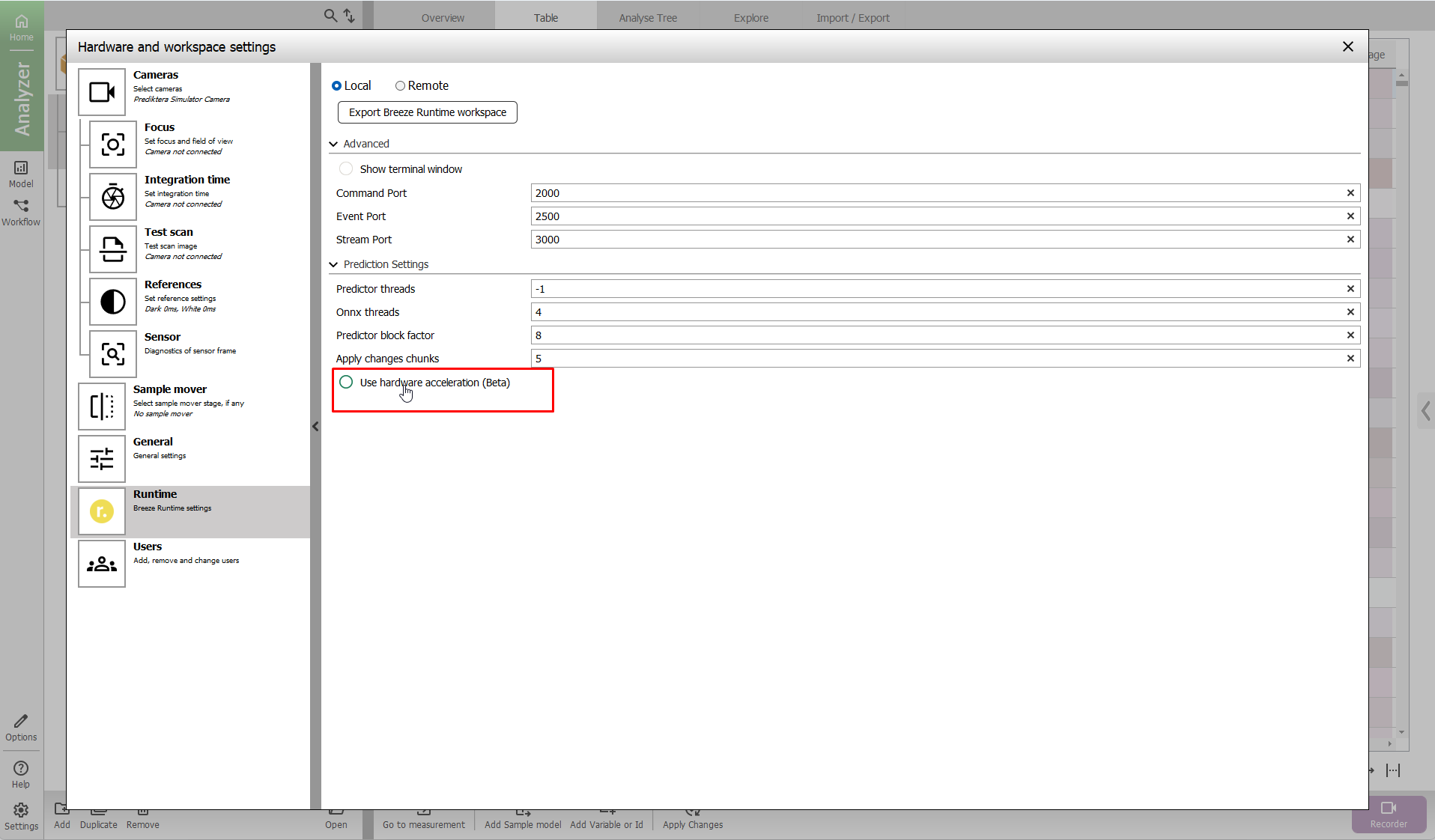
This functionality is currently in an experimental phase and may be used for evaluation purposes but should not be deployed in a production environment.
Currently Windows only (via DirectML)
To enable check the box in Settings:
Windows
The DirectML hardware-accelerated DirectX 12 library for machine learning requires any DirectX 12 capable device.
-
NVIDIA Kepler (GTX 600 series) and above
-
AMD GCN 1st Gen (Radeon HD 7000 series) and above
-
Intel Haswell (4th-gen core) HD Integrated Graphics and above
-
Qualcomm Adreno 600 and above
DirectML is compatible with Windows 10, version 1903 and newer. DirectML acceleration supports up to ONNX opset 17.
Linux
Support for CUDA and TensorRT is not supported as of Breeze 2024.1
Information below is deprecated
NVIDIA CUDA and TensorRT can be enabled in Linux (tested for Ubuntu 20.04) by adding the required files to the Runtime folder:
|
CUDA |
cuDNN |
TensorRT |
|---|---|---|
|
11.6 11.8 |
8.2.4 (Linux)
|
8.6 |
By downloading and using the software, you agree to fully comply with the terms and conditions of the https://docs.nvidia.com/cuda/eula/index.html . More information concerning the requirements see: https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirements
Inference
When applicable to following order of priority is used:
-
DirectML1 or CUDA2*
-
Generic CPU (MLAS)
CUDA
Enables hardware accelerated computation on Nvidia CUDA-enabled GPUs. Only available on Linux.
Supported matrix (see https://docs.nvidia.com/deploy/cuda-compatibility/index.html#support-hardware) :
|
CUDA Toolkit |
Linux x86_64 Driver Version |
Windows x86_64 Driver Version |
|
CUDA 11.x |
>= 450.80.02 |
>=456.39 |
1 Windows Only
2 Linux Only
*
No longer supported